Publications
 Fray: An Efficient General-Purpose Concurrency Testing Platform for the JVM
Fray: An Efficient General-Purpose Concurrency Testing Platform for the JVMAccepted at OOPSLA 2025
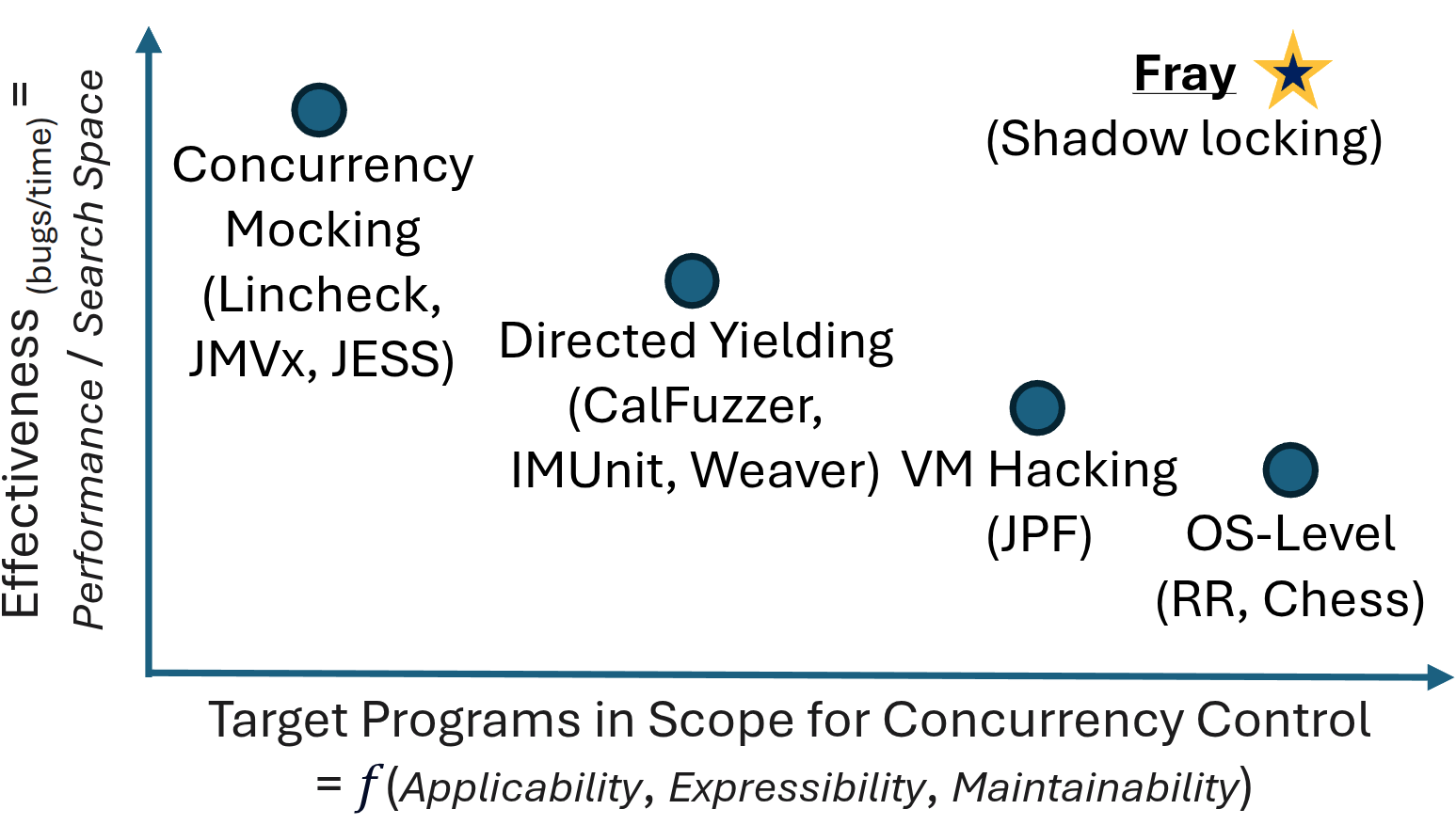
Concurrency bugs are hard to discover and reproduce, even in well-synchronized programs that are free of data races. In this paper, we take a first-principles approach for elucidating the requirements and design space to enable CCT on arbitrary real-world JVM applications. Based on these insights, we present Fray, a new platform for performing push-button concurrency testing beyond data races of JVM programs. The key design principle behind Fray is to orchestrate thread interleavings without replacing existing concurrency primitives, using a concurrency control mechanism called shadow locking for faithfully expressing the set of all possible program behaviors. We believe that Fray serves as a bridge between classical academic research and industrial practice--- empowering developers with advanced concurrency testing algorithms that demonstrably uncover more bugs, while simultaneously providing researchers a platform for large-scale evaluation of search techniques.'
 The Havoc Paradox in Generator-Based Fuzzing
The Havoc Paradox in Generator-Based FuzzingACM Transactions on Software Engineering and Methodology (2025)
Parametric generators combine coverage-guided and generator-based fuzzing for testing programs requiring structured inputs. They function as decoders that transform arbitrary byte sequences into structured inputs, allowing mutations on byte sequences to map directly to mutations on structured inputs, without requiring specialized mutators. However, this technique is prone to the havoc effect, where small mutations on the byte sequence cause large, destructive mutations to the structured input. This paper investigates the paradoxical nature of the havoc effect for generator-based fuzzing in Java. In particular, we measure mutation characteristics and confirm the existence of the havoc effect, as well as scenarios where it may be more detrimental.
 Can Large Language Models Write Good Property-Based Tests?
Can Large Language Models Write Good Property-Based Tests?Preprint
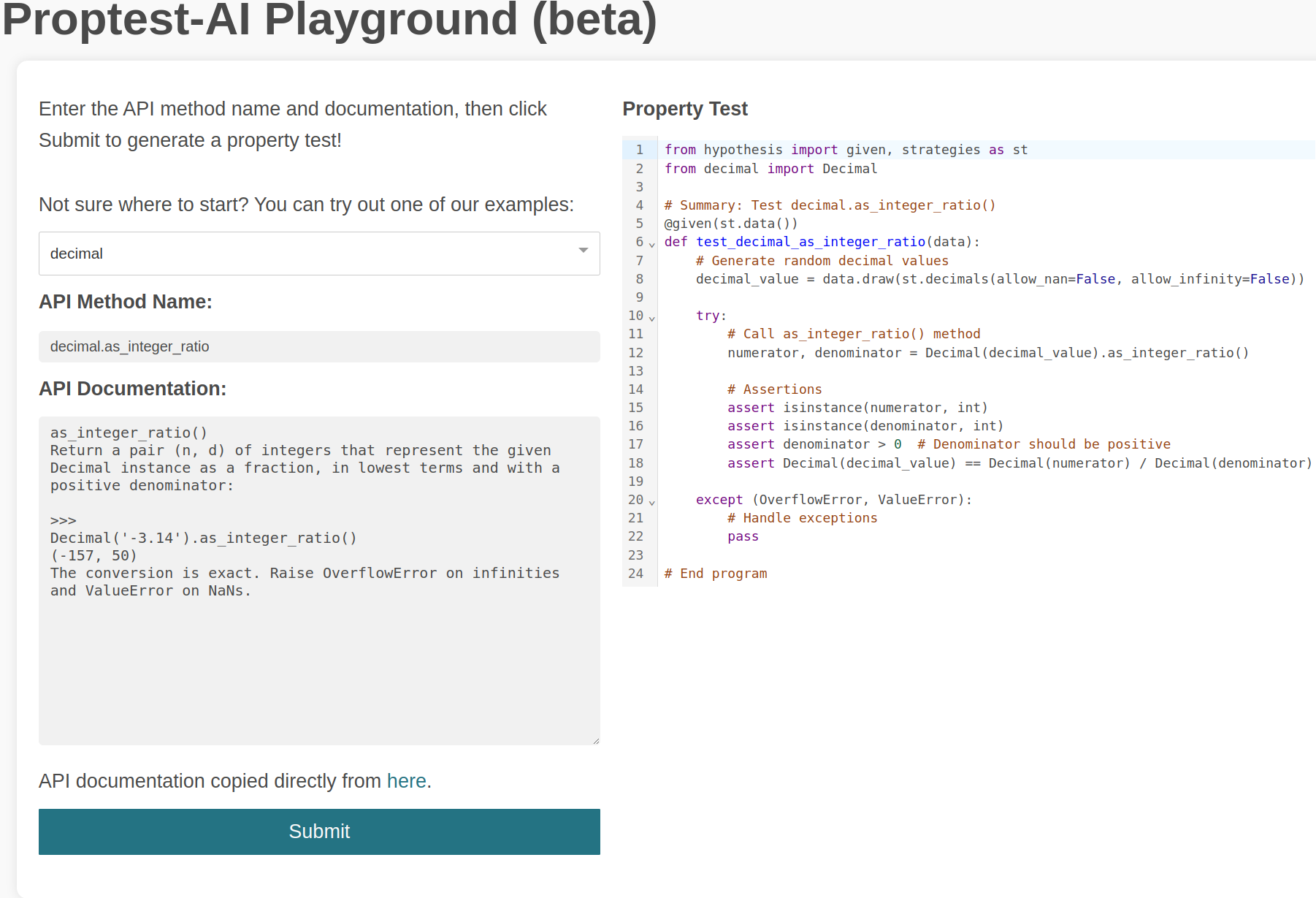
Property-based testing (PBT), while an established technique in the software testing research community, is still relatively underused in real-world software. Pain points in writing property-based tests include implementing diverse random input generators and thinking of meaningful properties to test. Developers, however, are more amenable to writing documentation; plenty of library API documentation is available and can be used as natural language specifications for property-based tests. As large language models (LLMs) have recently shown promise in a variety of coding tasks, we explore the potential of using LLMs to synthesize property-based tests. We call our approach Proptest AI, and propose three different strategies of prompting the LLM for PBT. We characterize various failure modes of Proptest AI and detail an evaluation methodology for automatically synthesized property-based tests. A prototype of our website can be found here.
 Pinning is Sinning: Towards Upgrading Maven Dependencies
Pinning is Sinning: Towards Upgrading Maven DependenciesPreprint
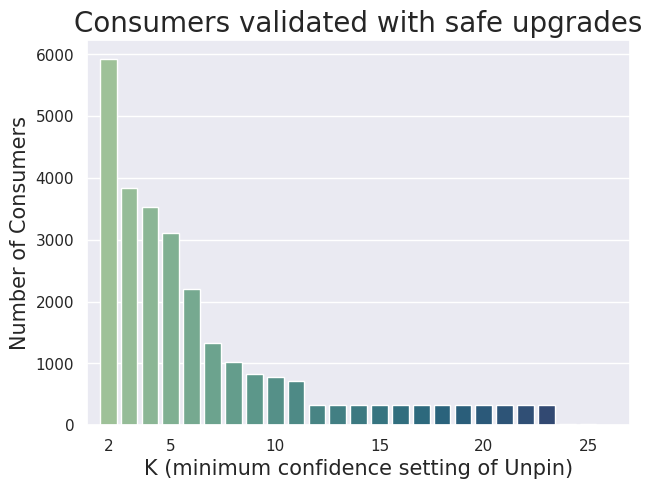
In this paper, we look to understand the frequency and consequences of dependency pinning. We conduct an empirical study to show that over 60% of consumers of popular Maven libraries pin their dependencies to outdated versions, some over a year old. Furthermore, these pinned versions often miss out on security fixes; we find that upgrading dependencies to the latest minor or patch version is 3.45x as likely to reduce security vulnerabilities rather than introduce new ones. We propose Unpin, a novel tool that computes a confidence score for a dependency upgrade by leveraging crowdsourced tests of peer projects and simulating the upgrade for them. Our evaluation on real-world pins to the top 500 popular libraries in Maven shows that Unpin (with a minimum confidence score of 5) can provide confidence to over 3,000 consumers to safely perform an upgrade that reduces security vulnerabilities.
 Guiding Greybox Fuzzing with Mutation Testing
Guiding Greybox Fuzzing with Mutation TestingISSTA 2023 (Distinguished Paper Award)
In this paper, we develop and evaluate Mu2, a Java-based framework for incorporating mutation analysis in the greybox fuzzing loop, with the goal of producing a test-input corpus with a high mutation score. Mu2 makes use of a differential oracle for identifying inputs that exercise interesting program behavior without causing crashes. This paper describes several dynamic optimizations implemented in Mu2 to overcome the high cost of performing mutation analysis with every fuzzer-generated input. These optimizations introduce trade-offs in fuzzing throughput and mutation killing ability, which we evaluate empirically on five real-world Java benchmarks. Overall, variants of Mu2 are able to synthesize test-input corpora with a higher mutation score than state-of-the-art Java fuzzer Zest.
 Growing a Test Corpus with Bonsai Fuzzing
Growing a Test Corpus with Bonsai FuzzingICSE 2021
This paper presents a coverage-guided grammar based fuzzing technique for automatically generating a corpus of concise test inputs for programs such as compilers. We walk through a case study of a compiler designed for education and the corresponding problem of generating meaningful test cases to provide to students. Our key insight is that instead of attempting to minimize convoluted fuzzer-generated test inputs, we can instead grow concise test inputs by construction using a form of iterative deepening. We call this approach bonsai fuzzing.